
¿Qué es y para qué sirven los modelos gráficos probabilísticos y cuál es su relación con las redes bayesianas?
Los modelos gráficos probabilísticos, incluidas las redes bayesianas, son modelos multidimensionales en los cuales, de acuerdo con un gráfico, la probabilidad conjunta, esto es aquella asociada con todas las variables es factorizada, representando un conjunto de independencias marginales y condicionales, también conocidas como propiedades de Markov. Por ejemplo, en una red no dirigida, la ausencia de un enlace entre dos variables indica que tales variables son condicionalmente independientes, dadas las variables restantes. En otras palabras, las variables se relacionan entre sí solo a través de las demás variables.
Los enlaces asociados con el gráfico pueden ser no dirigidos o dirigidos, en ambos casos se representa la independencia, pero en el último (redes bayesianas), la dependencia entre variables se representa a través de probabilidades condicionales correspondientes a una variable condicionada a los valores de las variables cuyas flechas apuntan a esta. Por ejemplo, considerando que dos nodos u y v apuntan a un nodo w, se dice que u y v son los nodos padres de w, y tenemos la densidad de probabilidad asociada con w dados valores específicos para u y v.
En la Tabla 1, se presenta cada tipo de modelo gráfico probabilístico y su nombre, los objetivos o la utilidad de cada modelo, y las limitaciones o problemas que se podría encontrar al usarlos. Aquí vemos que el nombre del modelo cambia de acuerdo con si se unen las variables de forma dirigida o no y del tipo de variable (cuantitativa o cualitativa) involucrada. De este gráfico vemos que en realidad una red bayesiana corresponde solo al caso en que se tienen variables cualitativas con enlaces dirigidos, aunque hay veces que ese nombre también se usa (quizás erróneamente) para cuando las variables son todas cuantitativas.
| Data learning | Data Type | Models | Goals | Disadvantages | |
| PGM | From data through structural learning (using algorithms, e.g. hc and pc) or using experts knowledge to build the network, associated probabilities, or both | Cualitativas | Loglinear graphical (undirected) | Understand marginal and conditional independences between variables | Computational time directly proportional to number of nodes, particularly for structural learning, thus, other techniques and/or graph restrictions (e.g. use of trees) can be necessary. Arcs direction or forbidding of certain direction must be validated by experts. Not all types of graphical models (particularly the mixed type) are as well developed, particularly in a same software. Gaussian distribution assumed in the continuous and mixed network types. |
| Discrete bayesian networks (directed) | Understand marginal and conditional independences between variables, understand causality between all variables (not just one), and evidence propagation (prediction and classification) | ||||
| Discrete chain models (both) | |||||
| Cuantitativas | Undirected Gaussian graphical models | Understand marginal and conditional independences between variables | |||
| Directed Gaussian graphical models | Understand marginal and conditional independences between variables, understand causality between all variables, and evidence propagation (prediction and classification) | ||||
| Gaussian chain graph models (directed and undirected) | |||||
| Mezcla | Mixed interaction models (undirected) | Understand marginal and conditional independences between variables | |||
| Mixed chain graph models (directed and/or unidrected) | Understand marginal and conditional independences between variables, understand causality betwen variables, and evidence propagation (prediction and classification) |
Tabla 1: Modelos gráficos probabilísticos, tipo de datos proporcionados por el usuario, tipo de variables admitidas y modelos asociados con cada tipo, así como objetivos y desventajas para cada modelo. Elaboración propia.
Para una mejor comprensión, en la Figura 1, mostramos un ejemplo práctico de una red bayesiana (red dirigida para datos cualitativos) relacionada con el daño arterial, en la cual se estudian distintas variables relacionadas con este problema. Incluimos las probabilidades condicionales asociadas (dependiendo de los nodos padres) y marginales (cuando no hay nodos padres). Por ejemplo, el padre de la variable hipertensión es sobrepeso y entonces tenemos la probabilidad de tener o no hipertensión condicionada tener sobrepeso, las cuales son en nuestro ejemplo 0.6 y 0.4, respectivamente. Cuando se involucran variables continuas, se aplican distribuciones gaussianas condicionales.
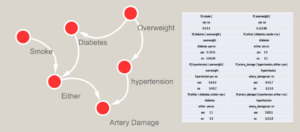
Figura 1. Red que representa un modelo relacionado con daño arterial. El sobrepeso puede considerarse como una causa tanto de la diabetes como de la hipertensión. Fumar y la diabetes están vinculados en un nodo (either) que indica si un sujeto fuma o tiene diabetes. La presencia de cualquiera de estos dos problemas, representados en el nodo llamado “either”, junto con la posible presencia de hipertensión, son posibles causas de daño arterial. Utilizando datos, o según el conocimiento de expertos, se pueden obtener las probabilidades condicionales y marginales asociadas con cada nodo, los valores posibles se muestran junto a la red. Elaboración propia.
Expertos pueden proporcionar la estructura de la red y los parámetros, e.g. las probabilidades condicionales en redes bayesianas como la de la Figura 1, asociados con los modelos según su conocimiento. También pueden aprenderse a partir de los datos mediante algoritmos y métodos estadísticos, o una combinación de ambos procesos. Debemos identificar relaciones coherentes, prohibiendo aquellas ilógicas o forzadas, utilizando diferentes algoritmos, comparando las redes obtenidas o simulando aleatoriamente varias redes para identificar las relaciones más repetidas. Por ejemplo, en el primer caso un algoritmo hc o hill-climbing puede partir de una red sin aristas o red trivial e ir agregando aristas comparando qué tanto un puntaje del buen ajuste de la red se modifica al agregar aristas, cambiarlas de dirección o quitarlas. En el segundo caso, se puede aplicar remuestreo (generar muchas muestras con remplazo de los datos) e ir aprendiendo en cada muestra una red diferente, las cuales pueden al final combinarse para generar una única red. Además, cuando se utilizan redes dirigidas, se deben validar las direcciones apropiadas.
En las redes bayesianas o modelos gráficos probabilísticos, también podemos asignar valores a un conjunto de nodos A (evidencia) y ver cómo estos valores afectan a otro conjunto de variables B, obteniendo la probabilidad condicional de esas variables en B dados valores específicos a los nodos en A. En consecuencia, estas redes pueden usarse para entender la dependencia, la causalidad o incluso para establecer una clasificación. Por ejemplo, en nuestra Figura 1, podemos generar un clasificador basado en redes bayesianas para determinar si bajo el modelo a un paciente nuevo al que le medimos las variables en la red le asignaríamos alta o baja probabilidad de tener un daño arterial.
Los modelos gráficos probabilísticos y las redes bayesianas representan la dependencia entre todas las variables al mismo tiempo y no asociaciones como en otros modelos comúnmente utilizados. Por ejemplo, el análisis de redes sociales (o SNA en inglés) es otro tipo de modelos matemáticos basados en gráficas, de los cuales hablaremos en otra ocasión, y que pueden tener más sentido para cuando estudiamos la asociación entre individuos sin incluir un aspecto probabilístico.
Conclusión: Los modelos gráficos probabilísticos son modelos cada vez más utilizados en análisis de datos, los cuales tienen un aspecto visual que los hace atractivos, además de interpretaciones probabilísticas que nos ayudan a entender mejor como se relacionan las variables. Principalmente, los modelos gráficos probabilísticos se aplican para analizar relaciones de direccionalidad en las asociaciones entre variables e incluso causalidad; para así ver cómo algunas variables afectan a otras en análisis con un enfoque descriptivo o en términos probabilísticos y también son muy usados con fines de clasificación.