
¿Qué es y para qué sirve la estadística espacial?
La disponibilidad de cada vez más información y fuentes requiere el uso de los análisis más sofisticados. Hay muchos datos georreferenciados, un término comúnmente utilizado en el marco de los Sistemas de Información Geográfica (SIG), que significa la asociación de mapas o imágenes con ubicaciones espaciales, es decir, posiciones en la superficie terrestre. Los SIG corresponden a la tecnología que une herramientas de manejo de información e informática para el análisis de datos espaciales, organizando y visualizándolos, produciendo mapas y permitiendo consultas y análisis espaciales.
La disponibilidad de datos espaciales suele ser de dos tipos: ráster (o archivos de imagen) o vectorial. Este último corresponde a puntos, líneas y polígonos, por ejemplo, representando ubicaciones de árboles en un área, ríos y provincias, respectivamente. Quizás el formato vectorial más conocido sea el shapefile, pero hay otros formatos.
Considerando que ya tenemos software para analizar información espacial, la pregunta es: ¿Qué tipo de análisis son posibles? La respuesta es que esto depende del tipo de datos y del objetivo de nuestro estudio. Por ejemplo, en un estudio más descriptivo, se puede estar interesado en representar zonas específicas y el transporte disponible entre ellas, identificando además a través de imágenes las características orográficas de las zonas. Esto se hace al ir uniendo distintas capas de información geográfica. Para los análisis usando estadística espacial, el tema que nos interesa, generalmente tenemos datos vectoriales, frecuentemente solo puntos o polígonos, y las preguntas están más relacionadas con aquellos comunes en estadística y ciencia de datos, por ejemplo: el mapeo de información, agrupamiento espacial, la predicción o explicación de una variable a través de otras considerando el aspecto espacial, etc.
Análisis descriptivo espacial: Como en la estadística clásica, el primer tipo de análisis que podríamos realizar es descriptivo. Esto consiste principalmente en mapear o, más específicamente, representar nuestros datos. Esto puede parecer fácil al principio, pero el proceso puede variar según los datos. Por ejemplo, dado que la tierra tiene forma esférica, necesitamos un sistema de coordenadas esféricas, generalmente latitud y longitud; sin embargo, es difícil obtener medidas en ese sistema, y por lo tanto se utilizan sistemas de coordenadas planas proyectando los datos de la esfera a un plano. También puede ser necesario unir capas de información; e.g. una capa de montañas y otra de centros de cultivo. Suponiendo que la información está organizada adecuadamente podemos iniciar el análisis descriptivo. Por ejemplo, considerando el desempleo por estados en un país, podríamos estar interesados en identificar los lugares en los que es mayor. Por supuesto, podríamos representar todos los valores posibles con un color diferente o incluso colorearlos según un gradiente de color; sin embargo, generalmente tratamos de agrupar la información, por ejemplo, calculando cuantiles y grupos asociados, representando cada uno con un color diferente, por ejemplo, de más oscuro a más claro. También podríamos identificar los estados que posiblemente sean valores atípicos, entre otras posibilidades.
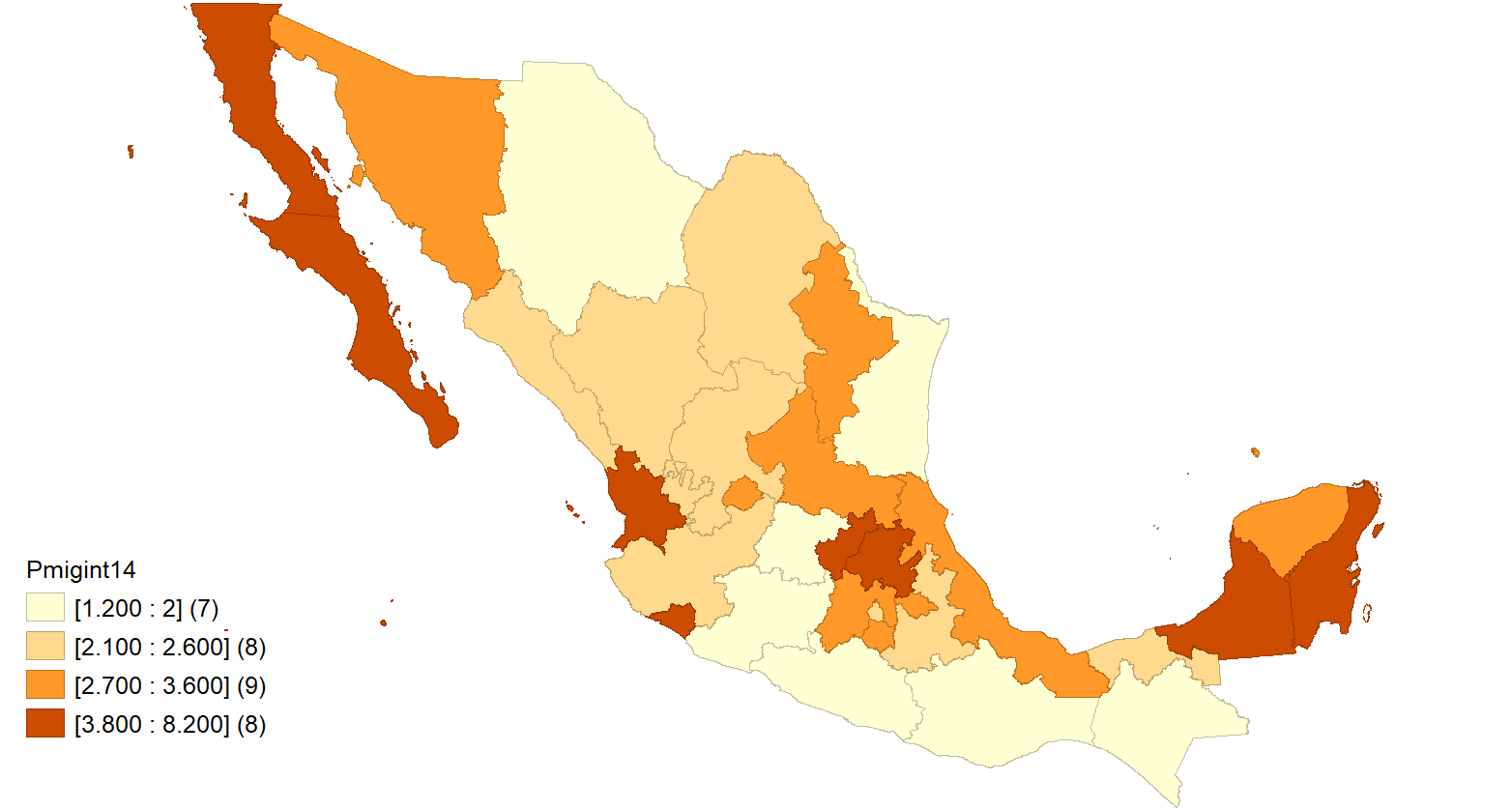
Figura 1: Cuartiles asociados a proporción de migración interna en México por estado. Elaboración propia.
Autocorrelación Espacial Global y Local: Dos aspectos que nos interesan al estudiar datos espaciales son si una variable está asociada espacialmente; es decir, si esperamos que lugares cercanos tengan valores similares y si hay agrupamiento espacial. Para poder analizar estos aspectos, necesitamos definir cuándo las unidades espaciales son vecinas y, a partir de ahí, definir una matriz de pesos espaciales W. Esta matriz se utiliza para calcular medidas de autocorrelación espacial, así como en algunos modelos lineales espaciales.
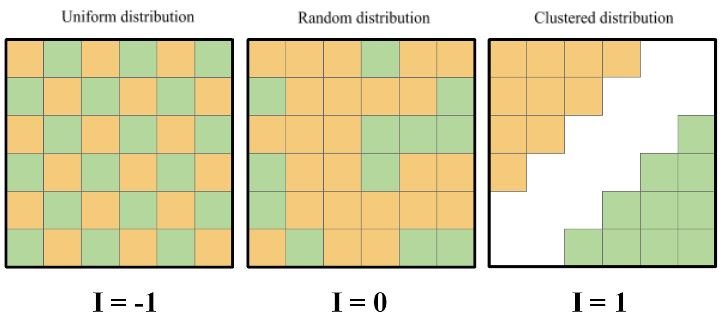
La I de Moran corresponde a un tipo de correlación, ponderada espacialmente según la matriz de pesos W. Tiene valores entre -1 y 1, con valores cercanos a cero indicando que no hay autocorrelación espacial, y valores positivos indicando autocorrelación positiva, es decir, valores grandes (pequeños) de la variable en una unidad espacial están asociados con valores grandes (pequeños) en sus vecinas, mientras que los valores negativos indican dispersión.
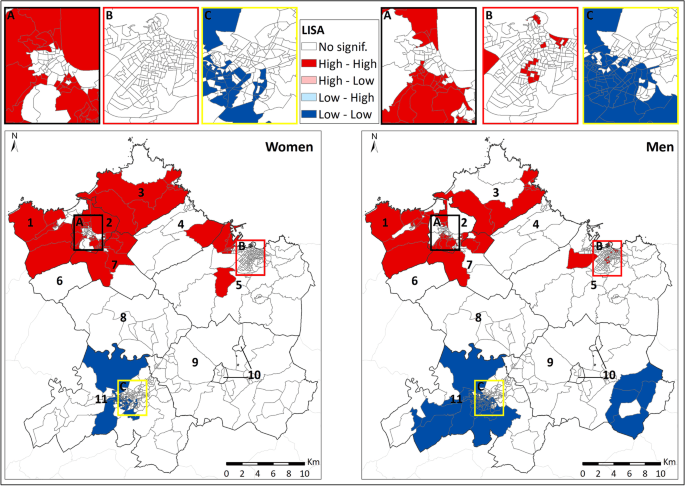
Podemos calcular la contribución de cada unidad sobre el I de Moran y se conoce como el indicador local de asociación espacial o LISA. Los mapas LISA se pueden obtener y usar para generar mapas de calor relacionados con la formación de agrupamientos espaciales significativos, lo que nos permite ver si una unidad espacial está rodeada de unidades espaciales con valores similares. Así podríamos por ejemplo obtener regiones en las que significativamente tenemos mayor pobreza en un país.
a)
b)
Figura 2. a) Distintos valores de la I de Moran, indicando que al acercarse a 1 genera conglomerados espaciales, mientras que al acercarse a -1 tiende a una dispersión (valores chicos y grandes de la variable intercalados) y b) Conglomerados espaciales de admisión por asma en Asturias, España, vemos como hay conglomerados de altas admisiones (unidades espaciales con valores altos rodeadas de valores con valores altos) en el norte.
Fuentes: https://www.50northspatial.org.ua/global-morans-i-spatial-autocorrelation/
González-Iglesias, V., Martínez-Pérez, I., Rodríguez Suárez, V. et al. Spatial distribution of hospital admissions for asthma in the central area of Asturias, Northern Spain. BMC Public Health 23, 787 (2023). https://doi.org/10.1186/s12889-023-15731-7
Interpolación y Geoestadística: Otra tarea importante en la estadística espacial consiste en interpolar información espacial, parte de la rama de la estadística llamada geoestadística, la cual analiza variables aleatorias asociadas con información espacial. En otras palabras, dada la información sobre una variable correspondiente a un conjunto de puntos, o centroides en el caso de polígonos, queremos predecir qué valores tomarán otro conjunto de puntos basándonos en esta información. Para poder realizar esto, primero necesitamos encontrar una regla de cómo una variable está asociada según la ubicación de los puntos, al menos en términos de la distancia entre ellos. El concepto de variograma, es útil en este proceso.
Variograma: Matemáticamente, tenemos un proceso aleatorio espacial Z(s), donde s corresponde a una unidad espacial en coordenadas geográficas, generalmente proyectadas, o en otras palabras, una variable aleatoria asociada con diferentes ubicaciones. Además, asumimos que este proceso es estacionario, lo que significa que la asociación entre los valores que una variable toma en dos ubicaciones solo depende de la distancia o el desfase espacial entre ellas. Así, una medida de la asociación entre los valores de la variable en dos ubicaciones separadas por una distancia h está dada por el variograma. Se utilizan modelos para encontrar el variograma adecuado a una variable, incluso en presencia de variables explicativas. De aquí obtenemos el covariagroma. En términos simples, obtenemos de nuestros datos las mejores reglas de asociación de una variable según la distancia que separa cada par de puntos y esto nos permite entender la correlación espacial entre una variable.
Interpolación Espacial Hay diferentes opciones para obtener una interpolación espacial; la primera corresponde a un promedio espacial y la segunda se basa en las ideas al definir el variograma.
Peso Inverso de la Distancia Predecimos el valor desconocido correspondiente a una ubicación espacial utilizando un promedio ponderado espacial, que se llama peso inverso de la distancia (IDW, por sus siglas en inglés). Las ponderaciones corresponden a una métrica que identifica la distancia entre el punto en el que se requiere la interpolación y los otros puntos.
Kriging En este caso, asumimos que los valores de nuestra variable de interés, dependiendo de diferentes ubicaciones, o proceso Z(s), pueden ser modelados linealmente de acuerdo con un conjunto de variables explicativas, considerando, como es habitual, un error aleatorio en el modelo.
Suponiendo que tenemos los valores de las variables explicativas sobre el punto s0 en el que queremos interpolar, x(s0), podemos predecir el valor desconocido de nuestra variable en el punto s0. En otras palabras, estimamos el valor desconocido de nuestra variable en una nueva ubicación como la suma de dos partes. La primera parte es una combinación lineal que depende de los valores que las variables explicativas toman en esta ubicación y los parámetros estimados, estos últimos dependiendo de los valores de nuestra respuesta y variables explicativas y la autocorrelación espacial en los puntos en los que se conocen los valores verdaderos de nuestra variable. La segunda parte corresponde a otra combinación lineal que consiste en la correlación espacial entre los valores de nuestra variable en la nueva ubicación y las otras ubicaciones y una medida del error entre los valores verdaderos de nuestra variable y los valores estimados.
Dado que necesitamos las varianzas y covarianzas espaciales para este proceso, o en otras palabras el covariograma C(h) si asumimos estacionariedad, primero obtenemos el variograma y el modelo asociado. Este tipo de interpolación se conoce como Kriging Universal.
Podemos realizar este proceso en cada punto en el que los valores de nuestra variable son desconocidos. Después de eso, incluso podemos obtener un mapa suavizado con valores predichos para una variable en diferentes ubicaciones.
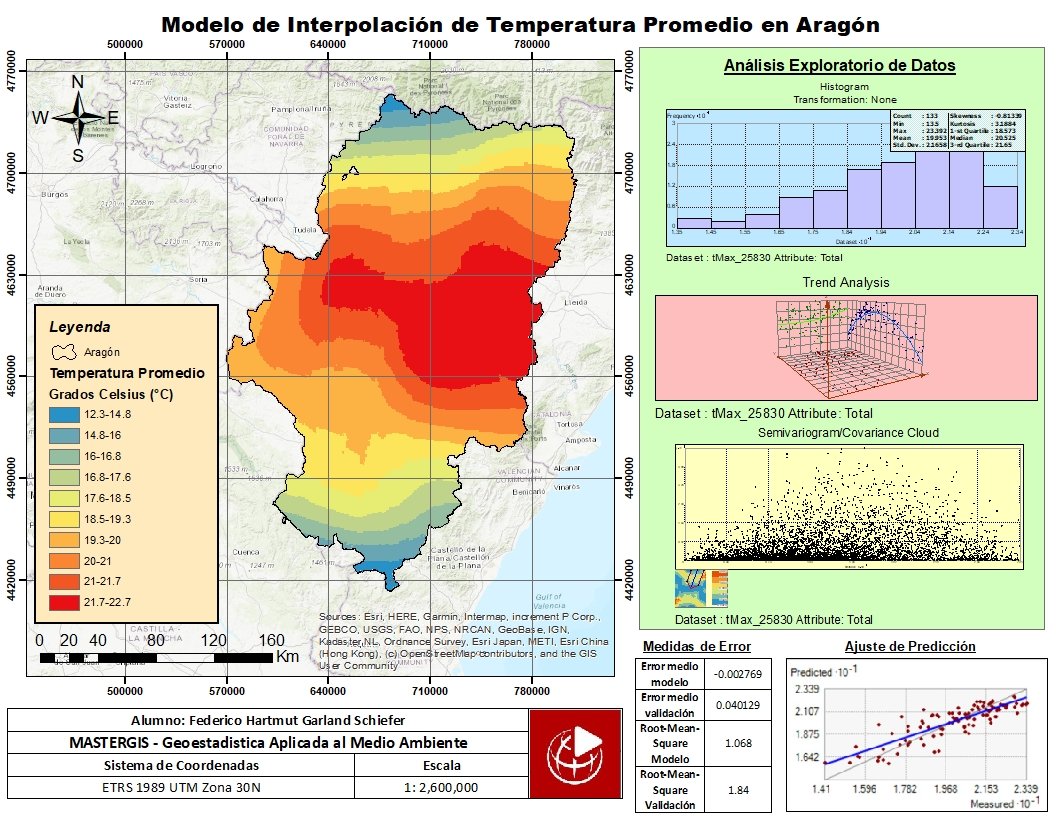
Figura 3: Mapa en el cual se muestra el uso de Kriging para obtener la temperatura promedio en Aragón a partir de la información dadas por las estaciones meteorológicas. A la derecha se muestra el semivariograma obtenido con los datos, a partir de los cuales se ajusta algún modelo adecuado que ayuda a ver el cambio en la relación de los valores que toma una variable en dos lugares a medida que la distancia aumenta.
Fuente: https://mastergis.com/proyecto/generacion-de-modelo-de-interpolacion-de-la-temperatura-promedio-en-aragon-espana-a-traves-del-metodo-kriging
Modelos Lineales para Datos Espaciales En esta parte, nuestro objetivo es explicar una variable de respuesta a través de un conjunto de variables explicativas, posiblemente incluyendo factores de confusión, considerando que cada observación corresponde a una de N unidades espaciales. Así, nuestro objetivo principal es explicar en lugar de predecir una variable. Por ejemplo, quisiéramos determinar en una muestra de localidades en México, si el nivel de pobreza está asociado con un indicador de la severidad de los problemas de delincuencia.
Para enfrentar este problema, una primera posibilidad es ajustar un modelo lineal clásico; sin embargo, es posible que haya autocorrelación espacial en los errores, violando así la independencia entre observaciones asumida en estos modelos. La posible autocorrelación espacial podría medirse sobre los residuos utilizando el índice de Moran, un variograma u otro método disponible. Si identificamos la existencia de autocorrelación espacial, deberíamos intentar usar otro tipo de modelo.
Una primera posibilidad es ajustar un modelo lineal considerando la heterocedasticidad inducida por la información espacial. Por ejemplo, podríamos considerar un estimador de mínimos cuadrados ponderados (WLS) considerando el tamaño de la unidad espacial como peso. También podríamos considerar un modelo ajustado por mínimos cuadrados generalizados (GLS) incluyendo la matriz de varianza y covarianza V que incluye la correlación espacial, por ejemplo, la derivada del variograma.
Otra posibilidad es usar variantes de modelos lineales que incluyan la correlación espacial mediante el uso de una matriz de pesos espaciales, W. Este caso incluye modelos en que se considera que la información de la respuesta en los vecinos de un lugar la afectan o que todo aquello que no es medido, esto es el error, en los vecinos de un lugar afectan el error en el lugar de interés.
Finalmente, la regresión ponderada geográficamente consiste en ajustar un modelo lineal para cada unidad espacial, considerando para el proceso de estimación la distancia entre una observación y el resto y su relación con la diferencia en la variación de la respuesta y su cambio según diferentes funciones de la distancia. Esto es, se usan estimadores de mínimos cuadrados ponderados, usados en modelos lineales cuando la varianza no es constante (heteroscedasticidad). Luego, podemos obtener mapas correspondientes a los coeficientes de las variables explicativas para cada unidad espacial, es decir, el efecto diferencial que una variable explicativa tiene sobre la respuesta en cada unidad espacial. Incluso podemos obtener predicciones sobre observaciones fuera de nuestra muestra.
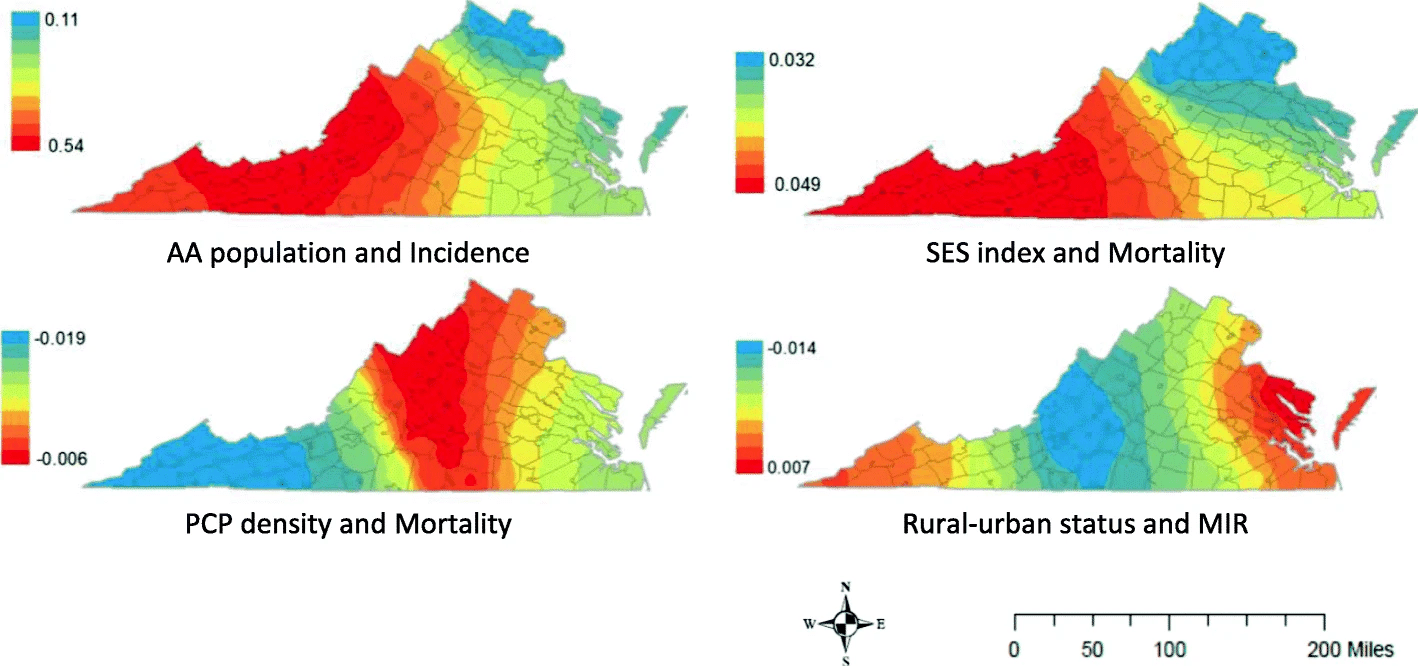
Figura 4: Cáncer colorectal en Virginia, EU, como función de distintos factores. Se ve el efecto diferencial de los distintos inputs según la región a través de los coeficientes locales obtenidos al ajustar una regresión geográficamente ponderada.
Fuente: Thatcher, E.J., Camacho, F., Anderson, R.T. et al. Spatial analysis of colorectal cancer outcomes and socioeconomic factors in Virginia. BMC Public Health 21, 1908 (2021). https://doi.org/10.1186/s12889-021-11875-6
Conclusión: Hemos introducido análisis espaciales que pueden ser útiles. Por supuesto, hay de más tipo, por ejemplo, análisis espacio-temporales, que consideran la información espacial a través del tiempo. Para estos hay una generelaizaicones de los métodos mostrados aquí; por ejemplo, Kriging o modelos lineales que incluyen simultáneamente las estructuras de correlación temporal y espacial. También hay modelos espaciales desde una perspectiva bayesiana, o métodos de agrupamiento que parten de considerar la información espacial como un proceso aleatorio en lugar de usar matrices de pesos. Sin embargo, el objetivo principal de este escrito es introducir a los lectores en los análisis espaciales, y no pretende ser un resumen de todos los métodos disponibles en la estadística espacial ni una revisión exhaustiva. Como tal, esperamos que se despierte en el lector la curiosidad e interés por estudiar este tema.